On Thu 08-01-09 20:57:28, Jan Kara wrote:But I think there are workloads for which this is suboptimal to say theAnd there's actually one more thing that probably needs some improvement
least. Imagine you do some crazy LDAP database crunching or other similar load
which randomly writes to a big file (big means it's size is rougly
comparable to your available memory). Kernel finds pdflush isn't able to
flush the data fast enough so we decrease dirty limits. This results in
even more agressive flushing but that makes things even worse (in a sence
that your application runs slower and the disk is busy all the time anyway).
This is the kind of load where we observe problems currently.
Ideally we could observe that we write out the same pages again and again
(or even pages close to them) and in that case be less agressive about
writeback on the file. But it feels a bit overcomplicated...
in the writeback algorithms:
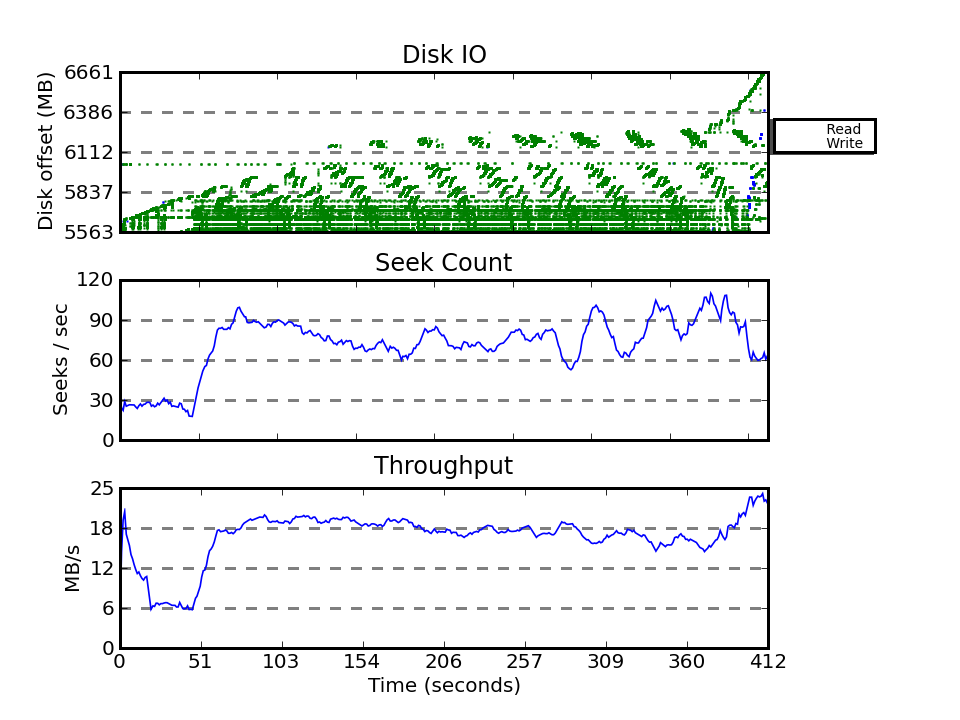
What we observe in the seekwatcher graphs is, that there are three
processes writing back the single database file in parallel (2 pdflush
threads because the machine has 2 CPUs, and the database process itself
because of dirty throttling). Each of the processes is writing back the
file at a different offset and so they together create even more random IO
(I'm attaching the graph and can provide blocktrace data if someone is
interested). If there was just one process doing the writeback, we'd be
writing back those data considerably faster...
This problem could have reasonably easy solution. IMHO if there is one
process doing writeback on a block device, there's no point for another
process to do any writeback on that device. Block device congestion
detection is supposed to avoid this I think but it does not work quite well
in this case. The result is (I guess) that all the three threads are calling
write_cache_pages() on that single DB file, eventually the congested flag
is cleared from the block device, now all three threads hugrily jump on
the file and start writing which quickly congests the device again...
My proposed solution would be that we'll have two flags per BDI -
PDFLUSH_IS_WRITING_BACK and THROTTLING_IS_WRITING_BACK. They are set /
cleared as their names suggest. When pdflush sees THROTTLING took place,
it relaxes and let throttled process to do the work. Also pdflush would
not try writeback on devices that have PDFLUSH_IS_WRITING_BACK flag set
(OK, we should know that *this* pdflush thread set this flag for the device
and do writeback then, but I think you get the idea). This could improve
the situation at least for smaller machines, what do you think? I
understand that there might be problem on machines with a lot of CPUs where
one thread might not be fast enough to send out all the dirty data created
by other CPUs. But as long as there is just one backing device, does it
really help to have more threads doing writeback even on a big machine?
Attachment:
trace.png
Description: PNG image
{kind=link}