ticket spinlock proportional backoff experiments
From: Michel Lespinasse
Date: Tue Jan 01 2013 - 19:06:52 EST
On Fri, Dec 21, 2012 at 3:49 PM, Rik van Riel <riel@xxxxxxxxxx> wrote:
> Many spinlocks are embedded in data structures; having many CPUs
> pounce on the cache line the lock is in will slow down the lock
> holder, and can cause system performance to fall off a cliff.
>
> The paper "Non-scalable locks are dangerous" is a good reference:
> http://pdos.csail.mit.edu/papers/linux:lock.pdf
>
> Proportional delay in ticket locks is delaying the time between
> checking the ticket based on a delay factor, and the number of
> CPUs ahead of us in the queue for this lock. Checking the lock
> less often allows the lock holder to continue running, resulting
> in better throughput and preventing performance from dropping
> off a cliff.
So as I mentioned before, I had a few ideas about trying to remove any
per-spinlock tunings from the equation and see if we can get good
performance with just one per-system tuning value. I recently had time
to run these experiments, so here are my current results.
I have based my experiments on v3.7 and used the synchro-test module
from Andrew's tree as an easily understandable synthetic workload (I
had to extend synchro-test to add a spinlock test, which I posted
separately to lkml a couple days ago: "[PATCH 0/2] extend synchro-test
module to test spinlocks too")
I tested 3 software configurations:
base: v3.7 + synchro-test ("mutex subsystem, synchro-test module",
"mutex-subsystem-synchro-test-module-fix",
"mutex-subsystem-synchro-test-module-fix-2", "kernel: fix
synchro-test.c printk format warrnings" and "add spinlock test to
synchro-test module")
auto: base + Rik's proposed patches ("x86,smp: move waiting on
contended ticket lock out of line", "x86,smp: proportional backoff for
ticket spinlocks", "x86,smp: auto tune spinlock backoff delay factor")
mine: base + Rik's "x86,smp: move waiting on contended ticket lock out
of line" + my two patches (which I'll attach as replies) "x86,smp:
simplify __ticket_spin_lock" (should be just cosmetic) and my own
version of "x86,smp: proportional backoff for ticket spinlocks". This
version differ's from Rik's principally by exporting the system-wide
tuning value through debugfs, and by using a delay of (ticket - head -
1) * spinlock_delay instead of just (ticket - head) *
spinlock_delay. Since spinlock_delay is a tunable parameter in my
experiments, I have been annotating my results with the spinlock_delay
value used in the experiment.
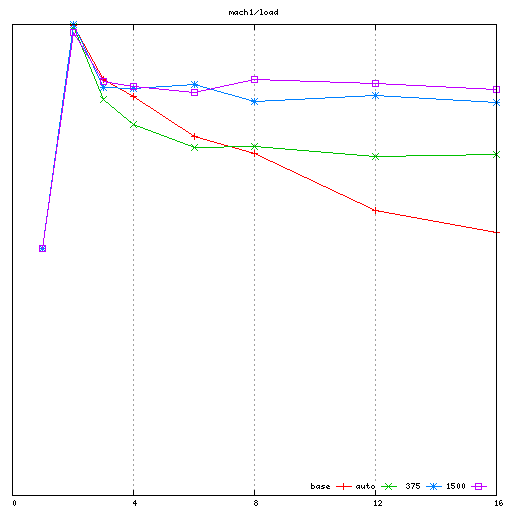
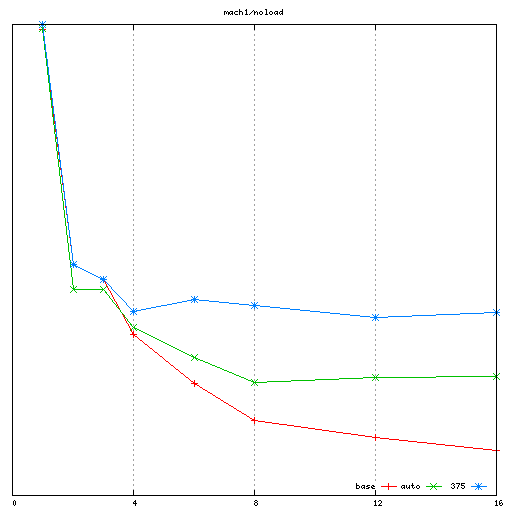
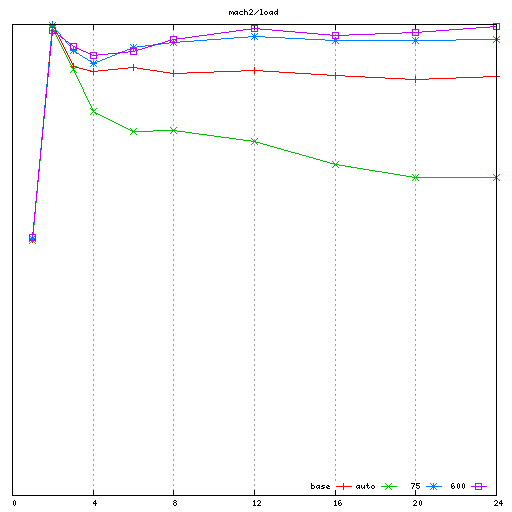
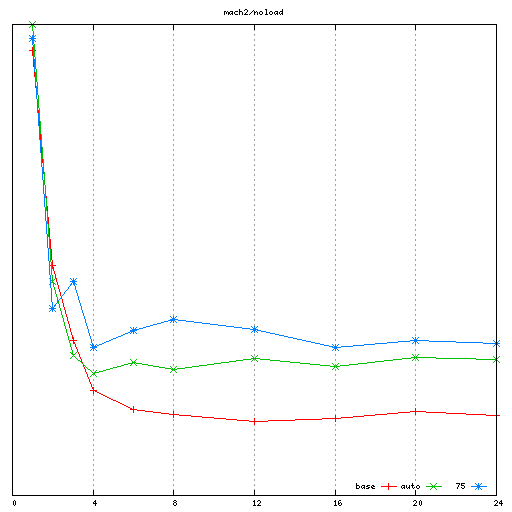
I have been testing on 3 machines:
mach1: 4 socket AMD Barcelona (16 cores total)
mach2: 2 socket Intel Westmere (12 cores / 24 threads total)
mach3: 2 socket Intel Sandybridge (16 cores / 32 threads total)
I ran two kinds of synthetic workloads using the synchro-test module:
noload: just N threads taking/releasing a single spinlock as fast as possible
load: N threads taking/releasing a single spinlock with 2uS loops
between each operation (2uS with spinlock held, 2uS with spinlock
released).
The test script looks like the following:
for i in 1 2 3 4 6 8 12 16 20 24 28 32; do
printf "%2d spinlockers: " $i
modprobe synchro-test sp=$i load=0 interval=0 do_sched=1 v=1 2>/dev/null || \
true
dmesg | sed 's/.*] //' | awk '/^spinlocks taken: / {sp=$3} END {print sp}'
done
(This is for the noload workload; the load workload is similar except for the load=0 interval=0 parameters being removed)
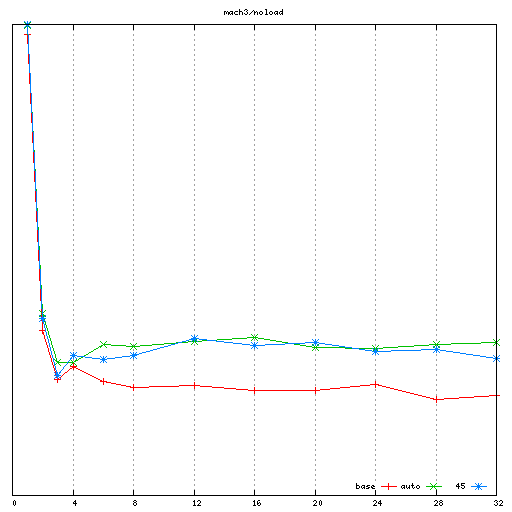
For each machine, I collected the noload performance results
first. When testing my patches, I did several runs and manually
adjusted the spinlock_delay parameter in order to get the best
performance. There is a bit of a line to walk there: too high and we
oversleep, thus reducing the lock utilization; too low and we do
excessive polling which reduces the lock throughput. However the tests
show that there is a small range of parameter values (~375 on mach1,
~75 on mach2, ~45 on mach3) which result in good performance
independently of the number of spinlocker threads.
mach3 was actually the tougher machine to tune for here. A tuning
value of 40 would have actually resulted in slightly higher
performance at 24-32 threads, and a value of 60 would have helped a
bit in the 6-12 threads range. However, we are only talking about
small percentage differences here - I think the main goal is to avoid
any large performance cliffs, and we certainly achieve that (note that
mach3 was already the best behaved of the 3 here)
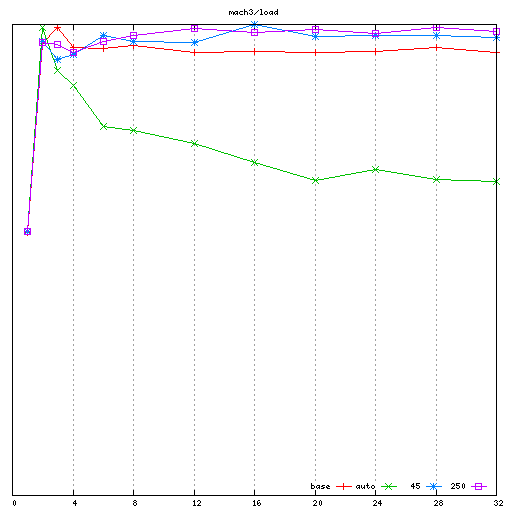
I then collected the "load" performance results (with a 2uS load with
spinlock held, and a 2uS interval with spinlock released). On each
machine, I collected baseline, auto (rik's proposal), my patches with
the spinlock_delay value that had been determined best for the
"noload" workload, and then I tried to manually tune the
spinlock_delay value for best performance on the "load" workload.
Analysis:
- In the "noload" workload, my proposal can (with some hand tuning)
result in better performance than rik's autotuned approach on mach1
and mach2, and be at rough parity on mach3. I believe the benefits
on mach1 and mach2 are due to achieving even lower coherency traffic
than rik's autotuned target of ~3.7 accesses per contended spinlock
acquisition. As it turns out, it was possible to find a single
spinlock_delay value that works well no mater how many spinlocker
threads are running. On this point, I only hit partial success on
mach3, as I was able to find a "decent all-around" value for
spinlock_delay that reached parity with Rik's proposal, but did not
beat it (and it seems that the optimal value did depend on the
amount of spinlocker threads in use)
- In the "load" workload, Rik's proposal performs poorly. This is
especially apparent on mach2 and mach3, where the performance
degradation due to coherency traffic in the baseline run wasn't very
high in the first place; the extra delays introduced to try and
avoid that coherency traffic end up hurting more than they help.
- In my proposal, tuning for the "noload" workload and applying that
to the "load" workload seems to work well enough. It may be possible
to get a few extra percent performance by using per-spinlock
tunings, but the difference is low enough that I would think it's
not worth the extra complexity. I like the simplicity of having one
single per-system tuning value that works well for any spinlocks it
might get applied to.
Of course, one major downside in my proposal is that I haven't figured
out an automatic way to find the most appropriate spinlock_delay
system tunable. So there is clearly some more experimentation needed
there. However, IMO the important result here is that our goal of
avoiding performance cliffs seems to be reachable without the
complexity (and IMO, risk) of per-spinlock tuning values.
--
Michel "Walken" Lespinasse
A program is never fully debugged until the last user dies.
Attachment:
mach1-load.png
Description: PNG image
Attachment:
mach1-noload.png
Description: PNG image
Attachment:
mach2-load.png
Description: PNG image
Attachment:
mach2-noload.png
Description: PNG image
Attachment:
mach3-load.png
Description: PNG image
Attachment:
mach3-noload.png
Description: PNG image
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}