[RFC PATCH 0/3] x86,smp: make ticket spinlock proportional backoffw/ auto tuning
From: Rik van Riel
Date: Fri Dec 21 2012 - 18:52:01 EST
Many spinlocks are embedded in data structures; having many CPUs
pounce on the cache line the lock is in will slow down the lock
holder, and can cause system performance to fall off a cliff.
The paper "Non-scalable locks are dangerous" is a good reference:
http://pdos.csail.mit.edu/papers/linux:lock.pdf
In the Linux kernel, spinlocks are optimized for the case of
there not being contention. After all, if there is contention,
the data structure can be improved to reduce or eliminate
lock contention.
Likewise, the spinlock API should remain simple, and the
common case of the lock not being contended should remain
as fast as ever.
However, since spinlock contention should be fairly uncommon,
we can add functionality into the spinlock slow path that keeps
system performance from falling off a cliff when there is lock
contention.
Proportional delay in ticket locks is delaying the time between
checking the ticket based on a delay factor, and the number of
CPUs ahead of us in the queue for this lock. Checking the lock
less often allows the lock holder to continue running, resulting
in better throughput and preventing performance from dropping
off a cliff.
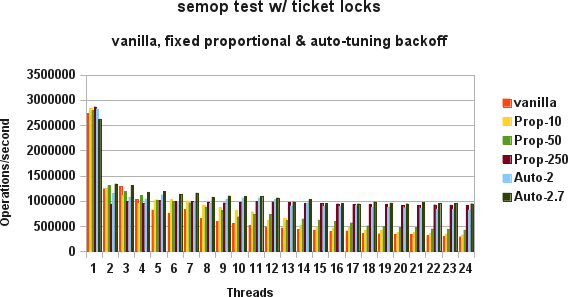
The test case has a number of threads locking and unlocking a
semaphore. With just one thread, everything sits in the CPU
cache and throughput is around 2.6 million operations per
second, with a 5-10% variation.
Once a second thread gets involved, data structures bounce
from CPU to CPU, and performance deteriorates to about 1.25
million operations per second, with a 5-10% variation.
However, as more and more threads get added to the mix,
performance with the vanilla kernel continues to deteriorate.
Once I hit 24 threads, on a 24 CPU, 4 node test system,
performance is down to about 290k operations/second.
With a proportional backoff delay added to the spinlock
code, performance with 24 threads goes up to about 400k
operations/second with a 50x delay, and about 900k operations/second
with a 250x delay. However, with a 250x delay, performance with
2-5 threads is worse than with a 50x delay.
Making the code auto-tune the delay factor results in a system
that performs well with both light and heavy lock contention,
and should also protect against the (likely) case of the fixed
delay factor being wrong for other hardware.
The attached graph shows the performance of the multi threaded
semaphore lock/unlock test case, with 1-24 threads, on the
vanilla kernel, with 10x, 50x, and 250x proportional delay,
and with autotuning proportional delay tuning for either 2 or
2.7 spins before the lock is obtained.
Please let me know if you manage to break this code in any way,
so I can fix it...
Attachment:
spinlock-backoff.png
Description: PNG image
{kind=link}