Re: [PATCH 3/9] writeback: bdi write bandwidth estimation
From: Wu Fengguang
Date: Sat Jul 23 2011 - 04:03:58 EST
On Sat, Jul 02, 2011 at 02:32:52AM +0800, Vivek Goyal wrote:
> On Wed, Jun 29, 2011 at 10:52:48PM +0800, Wu Fengguang wrote:
> > The estimation value will start from 100MB/s and adapt to the real
> > bandwidth in seconds.
> >
> > It tries to update the bandwidth only when disk is fully utilized.
> > Any inactive period of more than one second will be skipped.
> >
> > The estimated bandwidth will be reflecting how fast the device can
> > writeout when _fully utilized_, and won't drop to 0 when it goes idle.
> > The value will remain constant at disk idle time. At busy write time, if
> > not considering fluctuations, it will also remain high unless be knocked
> > down by possible concurrent reads that compete for the disk time and
> > bandwidth with async writes.
> >
> > The estimation is not done purely in the flusher because there is no
> > guarantee for write_cache_pages() to return timely to update bandwidth.
> >
> > The bdi->avg_write_bandwidth smoothing is very effective for filtering
> > out sudden spikes, however may be a little biased in long term.
> >
> > The overheads are low because the bdi bandwidth update only occurs at
> > 200ms intervals.
> >
> > The 200ms update interval is suitable, becuase it's not possible to get
> > the real bandwidth for the instance at all, due to large fluctuations.
> >
> > The NFS commits can be as large as seconds worth of data. One XFS
> > completion may be as large as half second worth of data if we are going
> > to increase the write chunk to half second worth of data. In ext4,
> > fluctuations with time period of around 5 seconds is observed. And there
> > is another pattern of irregular periods of up to 20 seconds on SSD tests.
> >
> > That's why we are not only doing the estimation at 200ms intervals, but
> > also averaging them over a period of 3 seconds and then go further to do
> > another level of smoothing in avg_write_bandwidth.
>
> What IO scheduler have you used for testing?
I'm using the default CFQ.
> CFQ now a days almost chokes async requests in presence of lots of
> sync IO.
That's right.
> Have you done some testing with that scenario and see how quickly
> you adjust to that change.
Jan has kindly offered nice graphs on intermixed ASYNC writes and SYNC
read periods.
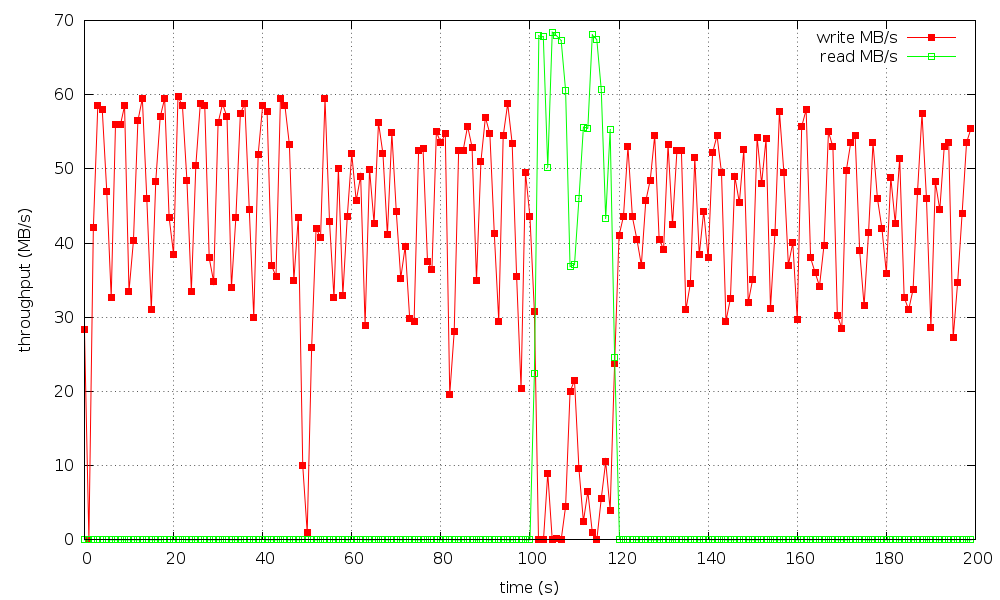
The attached graphs show another independent experiment of doing 1GB
reads in the middle of a 1-dd test on ext3 with 3GB memory.
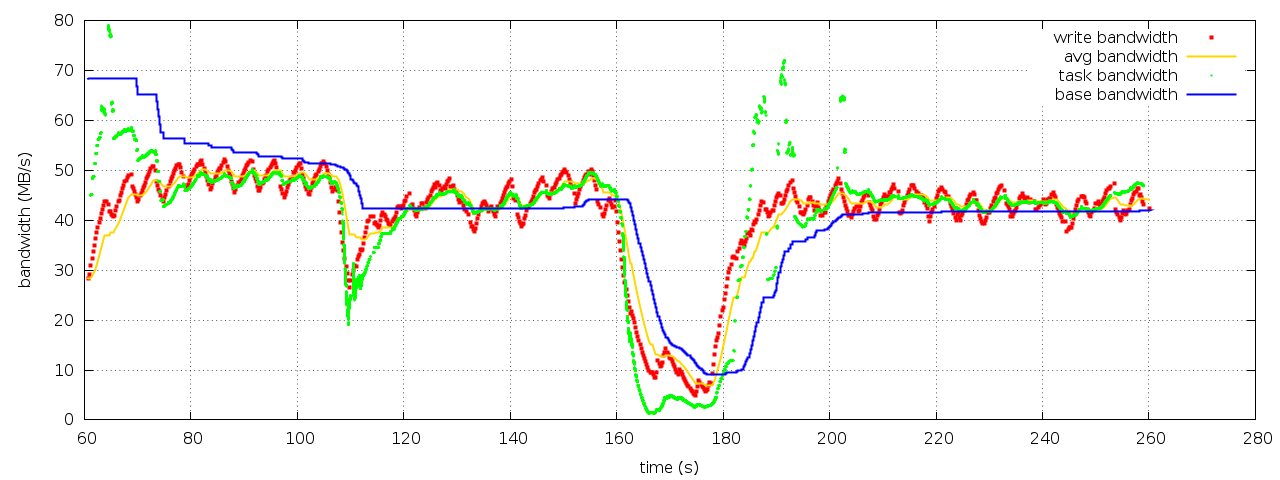
The 1GB read takes ~20s to finish. In the mean while, the write
throughput drops to around 10MB/s as shown by "iostat 1". In graph
balance_dirty_pages-bandwidth.png, the red "write bandwidth" and
yellow "avg bandwidth" curves show similar drop of write throughput,
and the full response curves are around 10s long.
> /me is trying to wrap his head around all the smoothing and bandwidth
> calculation functions. Wished there was more explanation to it.
Please see the other email to Jan. Sorry I should have written that
explanation down in the changelog.
Thanks,
Fengguang
Attachment:
iostat-bw.png
Description: PNG image
Attachment:
global_dirtied_written.png
Description: PNG image
Attachment:
global_dirty_state.png
Description: PNG image
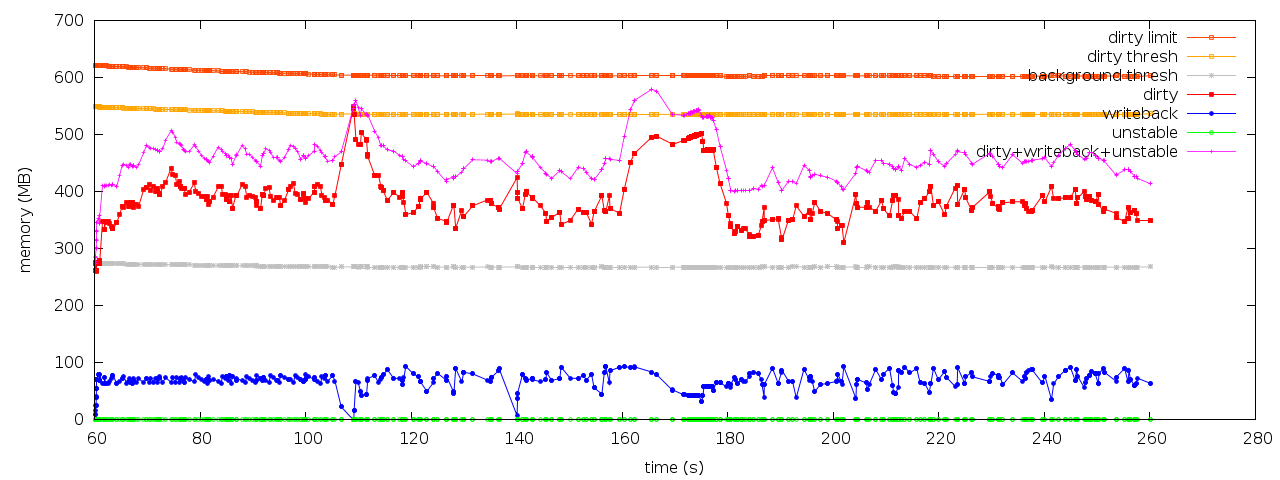
Attachment:
balance_dirty_pages-pages.png
Description: PNG image
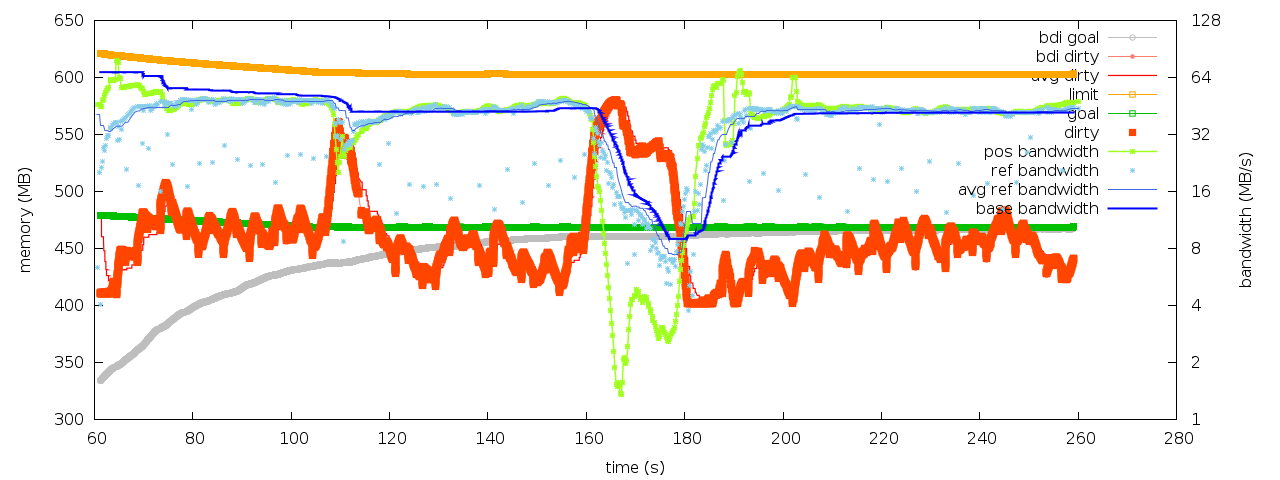
Attachment:
balance_dirty_pages-bandwidth.png
Description: PNG image
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}