On Sun, Apr 22, 2001 at 01:27:20AM +0100, D . W . Howells wrote:
> This patch (made against linux-2.4.4-pre6) makes a number of changes to the
> rwsem implementation:
>
> (1) Fixes a subtle contention bug between up_write and the down_* functions.
>
> (2) Optimises the i386 fastpath implementation and changed the slowpath
> implementation to aid it.
> - The arch/i386/lib/rwsem.c is now gone.
> - Better inline asm constraints have been applied.
>
> (3) Changed the sparc64 fastpath implementation to use revised slowpath
> interface.
> [Dave Miller: can you check this please]
>
> (4) Makes the generic spinlock implementation non-inline.
> - lib/rwsem.c has been duplicated to lib/rwsem-spinlock.c and a
> slightly different algorithm has been created. This one is simpler
> since it does not have to use atomic operations on the counters as
> all accesses to them are governed by a blanket spinlock.
I finally finished dropping the list_empty() check from my generic rwsemaphores.
The new behaviour of my rwsemaphores are:
- max sleepers and max simultanous readers both downgraded to 2^(BITS_PER_LONG>>1) for
higher performance in the fast path
- up_* cannot be recalled from irq/softirq context anymore
I'm using this your latest patch on top of vanilla 2.4.4-pre6 to benchmark my
new generic rwsemaphores against yours.
To benchmark I'm using your tar.gz but I left my 50 seconds run of the rwtest
with many more readers and writers to stress it a bit more (I posted the
changes to the rwsem-rw.c test in the message where I reported the race in your
semaphores before pre6).
Here the results (I did two tries for every bench and btw the numbers are
quite stable as you can see).
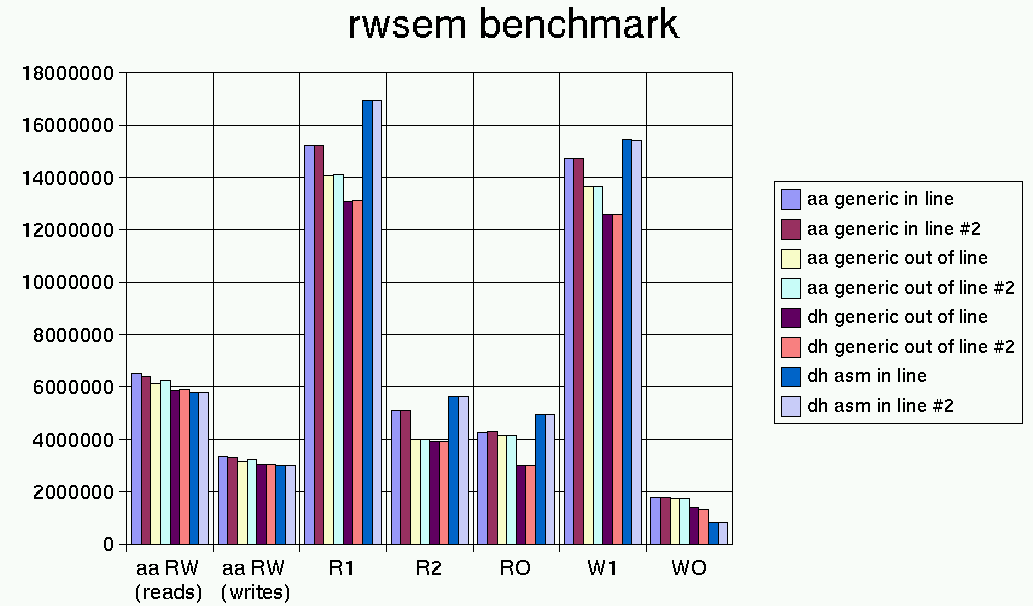
rwsem-2.4.4-pre6 + my new generic rwsem (fast path in C inlined)
rw
reads taken: 6499121
writes taken: 3355701
reads taken: 6413447
writes taken: 3311328
r1
reads taken: 15218540
reads taken: 15203915
r2
reads taken: 5087253
reads taken: 5099084
ro
reads taken: 4274607
reads taken: 4280280
w1
writes taken: 14723159
writes taken: 14708296
wo
writes taken: 1778713
writes taken: 1776248
----------------------------------------------
rwsem-2.4.4-pre6 + my new generic rwsem with fast path out of line (fast path in C out of line)
rw
reads taken: 6116063
writes taken: 3157816
reads taken: 6248542
writes taken: 3226122
r1
reads taken: 14092045
reads taken: 14112771
r2
reads taken: 4002635
reads taken: 4006940
ro
reads taken: 4150747
reads taken: 4150279
w1
writes taken: 13655019
writes taken: 13639011
wo
writes taken: 1757065
writes taken: 1758623
----------------------------------------------
RWSEM_GENERIC_SPINLOCK y in rwsem-2.4.4-pre6 + your latest #try2 (fast path in C out of line)
rw
reads taken: 5872682
writes taken: 3032179
reads taken: 5892582
writes taken: 3042346
r1
reads taken: 13079190
reads taken: 13104405
r2
reads taken: 3907702
reads taken: 3906729
ro
reads taken: 3005924
reads taken: 3006690
w1
writes taken: 12581209
writes taken: 12570627
wo
writes taken: 1376782
writes taken: 1328468
----------------------------------------------
RWSEM_XCHGADD y in rwsem-2.4.4-pre6 + your latest #try2 (fast path in asm in line)
rw
reads taken: 5789650
writes taken: 2989604
reads taken: 5776594
writes taken: 2982812
r1
reads taken: 16935488
reads taken: 16930738
r2
reads taken: 5646446
reads taken: 5651600
ro
reads taken: 4952654
reads taken: 4956992
w1
writes taken: 15432874
writes taken: 15408684
wo
writes taken: 814131
writes taken: 815551
To make it more readable I plotted the numbers in a graph (attached).
So my new C based rw semaphores are faster than your C based semaphores in
all tests and they're even faster than your x86 asm inlined semaphores when
there's contention (however it's probably normal that with contention the asm
semaphores are slower so I'm not sure I can make the asm inlined semaphore
faster than yours). I will try to boost my new rwsem with asm in the fast path
now (it won't be easy but possibly by only changing a few lines of the slow
path inside an #ifdef CONFIG_...) to see where can I go. Once I will have an
asm inlined fast path for >=486 integrated I will upload a patch but if you
want a patch now with only the new generic C implementation to verify the above
numbers let me know of course (ah and btw the machine is a 2-way PII 450mhz).
I think it's interesting also the comparison of my generic rwsem when inlined
and not inlined (first four columns). BTW, I also tried to move my only lock in
a separated cacheline (growing the size of the rwsem over 32bytes) and that
hurted a lot.
Note also the your wo results with your asm version (the one in pre6 + your
latest try#2) is scoring more than two times worse than my generic semaphores.
Andrea
This archive was generated by hypermail 2b29 : Mon Apr 23 2001 - 21:00:43 EST
{kind=link}